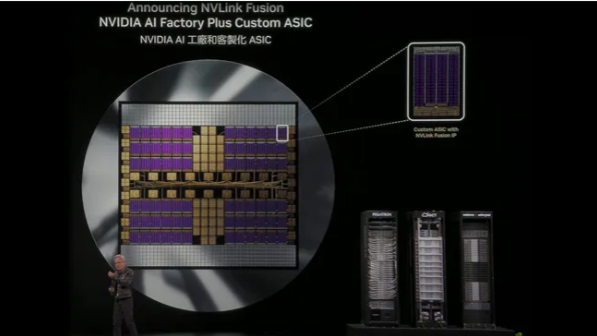
NVLink Fusion یک چارچوب سیلیکونی و IP جدید از شرکت NVIDIA است که در نمایشگاه Computex در ماه مه ۲۰۲۵ معرفی شد. این فناوری نسل پنجم سیلیکون سفارشی است که برای ارتباط سریعتر بین پردازندههای هوش مصنوعی طراحی شده است و به شرکتهای دیگر مانند Fujitsu ، Qualcomm، MediaTek، Marvell، Alchip و سایر شرکای صنعتی اجازه میدهد تراشههای اختصاصی خود را به معماری مراکز داده NVIDIA از طریق NVLink متصل کنند.
مزایا:
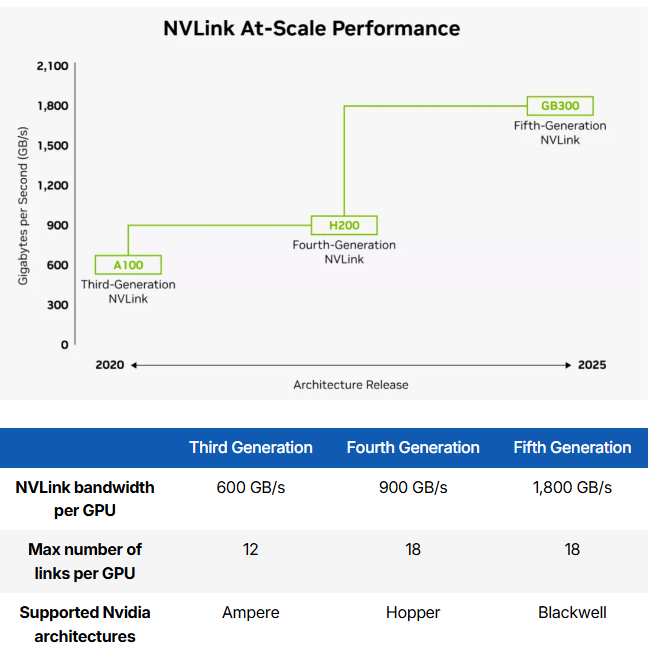
- فناوری NVLink انویدیا یک اتصال اختصاصی (proprietary interconnect) برای ارتباط مستقیم میان GPU به GPU و CPU به GPU است که پهنای باند بسیار بالاتر و تاخیر بسیار کمتری نسبت به رابط استاندارد PCIe ارائه میدهد.
با وجود اینکه NVLink همچنان از رابط الکتریکی استاندارد PCIe استفاده میکند، اما از نظر عملکرد تا ۱۴ برابر پهنای باند بیشتری نسبت به PCIe معمولی فراهم میکند. این فناوری نقش کلیدی در افزایش سرعت ارتباط میان پردازندهها در سیستمهای محاسباتی سنگین و هوش مصنوعی دارد، جایی که انتقال سریع دادهها میان GPU ها و CPUها برای رسیدن به عملکرد بهینه ضروری است.
- معماری انعطافپذیر : ارائهدهندگان خدمات ابری و هایپراسکیلرها میتوانند پردازندههای NVIDIA مانند Grace) یا GPU های( آن را با تراشههای اختصاصی خود ترکیب کرده و کارخانههای هوش مصنوعی سفارشی بسازند.
در نسلهای گذشته، فناوری NVLink انویدیا تنها به ارتباط درون یک نود سرور محدود میشد، اما با اضافه شدن تراشههای اختصاصی NVLink Switch ، این امکان فراهم شد که NVLink به معماریهای در مقیاس رک (rack-scale) گسترش یابد. این تحول به انویدیا اجازه داد تا کلاسترهای عظیمی از GPUها را در کنار هم برای اجرای همزمان بارهای سنگین هوش مصنوعی به کار بگیرد. این مزیت باعث شد NVLink به یک برتری کلیدی برای انویدیا تبدیل شود؛ برتریای که رقبایی مانند AMD و Broadcom هنوز نتوانستهاند با آن برابری کنند.
با این حال، NVLink یک رابط اختصاصی است و بهجز همکاری اولیه این شرکت با IBM، انویدیا عمدتاً این فناوری را فقط برای محصولاتی که از سیلیکون خود انویدیا استفاده میکنند، محدود نگه داشته بود.

در سال ۲۰۲۲، انویدیا فناوری C2C (Chip-to-Chip) خود را معرفی کرد؛ این فناوری یک رابط ارتباطی بینتراشهای (inter-die/inter-chip) است که شرکتها میتوانستند از آن برای برقراری ارتباط بین سیلیکون خود و GPUهای انویدیا استفاده کنند. این ارتباط از پروتکلهای استاندارد صنعتی مانند Arm AMBA CHI و CXL بهره میبرد. اما حالا برنامه NVLink Fusion بسیار فراتر از C2C عمل میکند و راهکارهایی در مقیاس بالا برای ارتباط گسترده در معماریهای Rack-Scale فراهم میسازد.
NVLink Fusion این پارادایم را تغییر میدهد: شرکتهایی مانند Fujitsu و Qualcomm اکنون میتوانند این رابط را با پردازندههای اختصاصی خود ترکیب کنند، که این موضوع گزینههای جدیدی را در طراحی سیستمهای پیشرفته باز میکند. قابلیت NVLink از طریق یک چیپلت (chiplet) در کنار بسته محاسباتی (compute package) یکپارچه شده است.
انویدیا همچنین پشتیبانی از شتابدهندههای سیلیکونی سفارشی مانند ASICها را از شرکتهایی مانند MediaTek، Marvell و Alchip فراهم کرده تا آنها نیز بتوانند در کنار پردازندههای Grace انویدیا به صورت هماهنگ کار کنند. همچنین شرکت Astera Labs نیز به اکوسیستم پیوسته تا ظاهراً سیلیکونهای ارتباطی مخصوص NVLink Fusion را تأمین کند. شرکتهای نرمافزار طراحی تراشه، مانند Cadence و Synopsys نیز به این برنامه پیوستهاند تا ابزارها و IPهای طراحی مورد نیاز را برای پشتیبانی از این اکوسیستم فراهم کنند.
این فناوری با کاهش تأخیر و افزایش توان عملیاتی، امکان پردازش مدلهای پیچیده هوش مصنوعی را بهینهسازی میکند. ویژگیهای کلیدی شامل موارد زیر است:
- ارتباطات فوق سریع: انتقال داده با ۸۰۰ گیگابیت بر ثانیه برای هر پردازنده گرافیکی
- بهبود عملکرد هوش مصنوعی: افزایش ۱.۳ تا ۱.۴ برابر قدرت پردازشی در سطح رک
- معماری مقیاسپذیر: امکان ادغام با پردازندههای سفارشی و زیرساختهای ابری
- مدیریت هوشمند: استفاده از نرمافزار Mission Control برای کنترل و نظارت بر سیستمهای هوش مصنوعی
فناوری NVLink Fusion با همکاری شرکتهایی مانند MediaTek ، Marvell، Alchip، Astera Labs، Synopsys و Cadence توسعه یافته است و در مراکز داده پیشرفته برای ساخت کارخانههای هوش مصنوعی مورد استفاده قرار خواهد گرفت.